EARL: Expanding the Action Space of LLMs to Reason Beyond Language

*Equal Contribution. zhongqi@chalmers.se, weishi.wang@sap.com
TL;DR: We propose a new paradigm for post-training LLMs with external environments to incentivize reasoning and agentic behavior, showing promising results.
Currently, interactions with external environments must be expressed through text in predefined formats, parsed, and routed to external interfaces. This overloads the model’s language with both reasoning and control duties, and requires a hand-crafted parser, external to the LLM. To address this, we decouple environment interactions from language by internalizing them in an Expanded Action space (ExpA), beyond the vocabulary. We illustrate how ExpA differs from traditional paradigm later. ExpA leads to promising results in 3 key areas.
1. Multi-turn Contingent Planning
Many challenging reasoning tasks require not only multi-turn interactions with external environments but also adaptive decision-making based on intermediate feedback. In our Countdown task (example in Figure 1 caption), agents must use an external calculator to reach a target number. Each problem admits up to 7,680 unique combinations, demanding efficient reasoning and dynamic strategy adjustment (e.g., shifting tactics when far from the target). Agents trained with ExpA Reinforcement Learning (EARL) significantly outperform strong vocabulary-constrained baselines (Figure 1). Qualitative analysis (Table 1) further shows that the EARL agent respond more sensitively to intermediate observations, a key trait of effective planning.
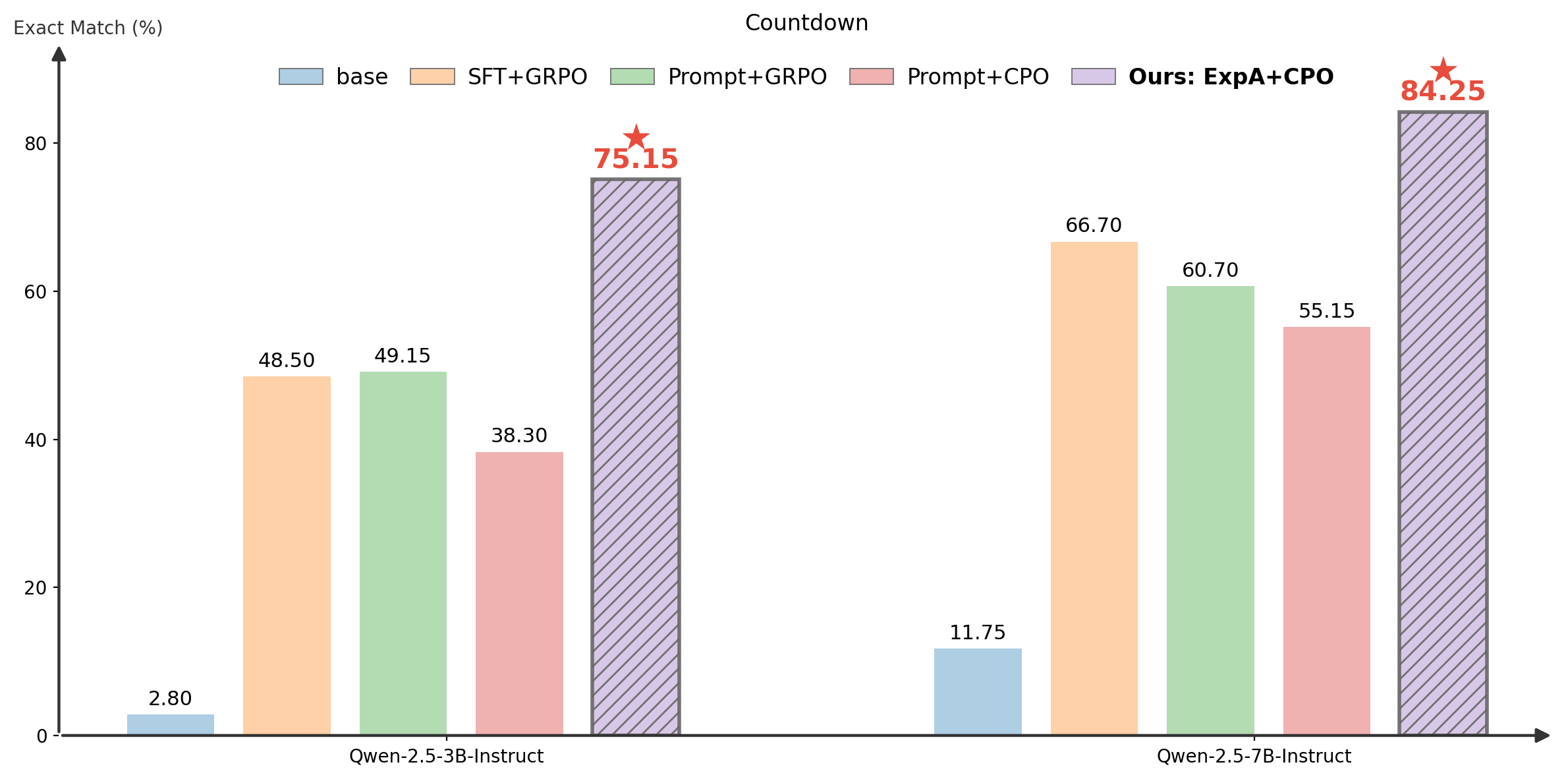
Figure 1. Exact Match (%) comparison on the Countdown task (Example: "Using the numbers [2900, 1205, 5911, 4], create an equation that equals -4212."). We fine-tune Qwen2.5-3B and Qwen2.5-7B on a multi-task benchmark that includes Countdown as a sub-task, and evaluate them on a held-out Countdown test set. Full benchmark results are provided in the paper.
| Phrase | EARL | Prompt+CPO | Prompt+GRPO | SFT+GRPO |
|---|---|---|---|---|
| not close | 9,961 | 99 | 0 | 18 |
| is close | 805 | 2,930 | 0 | 855 |
| close to | 3,019 | 1,138 | 0 | 2,253 |
| still close | 9 | 193 | 0 | 0 |
| different approach | 7,586 | 92 | 1,650 | 15 |
| another approach | 0 | 1,769 | 0 | 219 |
| different combination | 8,851 | 39 | 2,040 | 377 |
| another combination | 1,784 | 46 | 0 | 58 |
| negate | 682 | 4 | 0 | 121 |
| far from | 8,264 | 141 | 0 | 10 |
| Total | 40,961 | 6,451 | 3,690 | 3,926 |
2. Partially Observed Environment
In agentic settings, LLMs can extend their reasoning into external environments by mapping language instructions into operations such as API calls or robotic control, allowing them to solve tasks in the digital or physical worlds. Such scenarios are typically partially observed, where the agent must interact with the environments to access their hidden states.
In this work, we train agents to order a set of hidden numbers using compare and swap environments, e.g., “compare A, B” reveals their relation, while “swap A, B” updates the hidden state. This task is challenging, as the agent must plan contingently from comparison outcomes, reason precisely over first-order relations, and manipulate hidden states through interactions rather than text output, which makes this a realistic testbed for interactive decision-making situations such as embodied AI.
Interestingly, agents with ExpA achieves perfect Sort-4 accuracy with just 70 training steps, while self-discovering an efficient algorithm competitive with classical designs (Figure 2).
Figure 2. An example for reasoning with expanded actions.
3. Readiness for Zero-RL
To promote effective exploration of the expanded action space and new environments, we introduce ExpA Reinforcement Learning (EARL) with counterfactual policy optimization, which fully supports RL on base models, i.e., without requiring supervised tool-call data or adherence to predefined language patterns.
Approach
We propose a fundamental shift from the language-only paradigm for interacting with environments (Figure 3). Our aim is threefold:
- Decouple environment interactions from language reasoning
- Enable end-to-end training by removing reliance on external parsers and keeping interactions under the model’s control.
- Fully support RL on base models, i.e., Zero-RL, without requiring supervised tool-call data or adherence to predefined language patterns.
We propose to expand the LLM’s action space for interactions (Figure 4), and derive a training strategy to explore these interactions while supporting Zero-RL (Figure 5).
Figure 3. A simple example for reasoning with vocabulary-based interactions.
Interactions by Vocabulary
In current works, LLMs can be viewed as agents acting in decision processes with an action space restricted to vocabulary. Interactions with external environments are mediated through a parser, which translates predefined text patterns (e.g., tool tags or structured JSON) into environment-specific actions, routed to the corresponding environment. The environment executes the actions and returns a plain-text observation, which is appended to the model's context.
Figure 4. An example for reasoning with expanded actions.
Interactions by Expanded Actions
We decouple environment interactions from language by internalizing them in an Expanded Action space (ExpA), beyond the vocabulary. The model starts reasoning in the default language environment, but may trigger routing actions and switch to an external environment at any time. From there, the model can only invoke environment-specific actions, receive feedback from the environment, and potentially route back to language as a result. This enable end-to-end training by removing reliance on external parsers and keeping interactions under the model’s control.
Figure 5. An example of counterfactual policy optimization, which involves both factual and counterfactual rollouts.
EARL with Counterfactual Policy Optimization
To promote effective exploration of the expanded action space and new environments, we employ ExpA with RL (ExpA). During training, for each (factual) rollout, we construct a counterfactual rollout by forcing a routing action at a plausible intermediate step, identified as a position where the model assigns high probability to the routingdescription token. The advantage is then computed as the difference between the counterfactual and original rewards, thereby encouraging exploration of rarely visited but essential environments.
BibTeX
@misc{2510.07581,
Author = {Zhongqi Yue and Weishi Wang and Yundaichuan Zhan and Juncheng Li and Daniel Dahlmeier and Fredrik D. Johansson},
Title = {Expanding the Action Space of LLMs to Reason Beyond Language},
Year = {2025},
Eprint = {arXiv:2510.07581},
}